

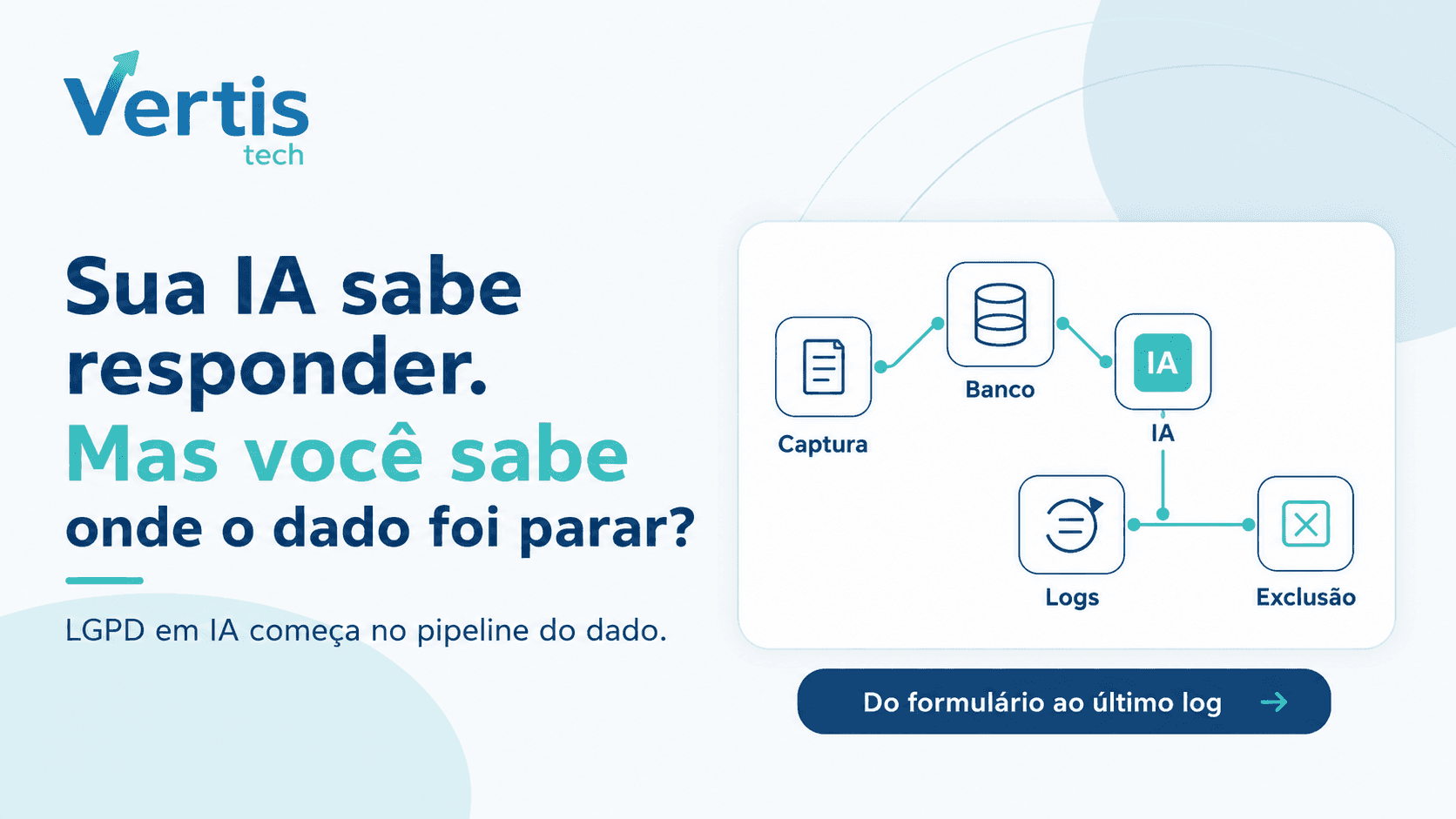
A proposta de chatbot, agente de IA ou RAG corporativo está pronta pra assinatura. O escopo descreve fluxos, integrações, modelo de linguagem, SLA. O que quase nunca aparece é o mapa de onde o dado pessoal do cliente final vai parar — em quais bancos, em qual jurisdição, com qual base legal, por quanto tempo, e o que acontece quando esse cliente pedir exclusão no ano que vem.
A LGPD não desaparece porque o dado virou "contexto" do modelo. A Agenda Regulatória 2025-2026 da ANPD incluiu inteligência artificial como tema prioritário, e a Nota Técnica nº 12/2025 já sinaliza preocupação explícita com "grandes volumes de dados para treinamento de modelos sem clareza suficiente sobre finalidade, retenção, base legal e compartilhamentos internacionais". O decisor que assina um contrato de IA sem mapear o pipeline do dado herda o passivo — não o fornecedor.
Principais pontos
- O dado pessoal do cliente final atravessa um pipeline técnico, não um sistema único, e cada estágio tem regime LGPD próprio.
- Embedding vetorial em pgvector não é dado anonimizado, é dado pessoal transformado — e direito de exclusão precisa alcançar lá também.
- Prompts enviados a um LLM externo podem ser retidos pelo provedor, com jurisdição e prazo definidos por ele, não pelo contratante.
- ANPD priorizou IA na agenda regulatória 2026-2027, com fiscalização sobre finalidade, retenção e transferência internacional.
- A pergunta que o decisor precisa fazer ao fornecedor não é "vocês são LGPD-compliant", é "me mostre o caminho de um nome e CPF do meu cliente desde o formulário até o último log".
Pra empresas avaliando fornecedor de IA aplicada, a pergunta operacional não é mais "qual modelo vocês usam". É "quem é controlador, quem é operador, quais subprocessadores aparecem no contrato, e como o direito de exclusão do meu cliente final é honrado dentro do índice vetorial e dos logs de conversa". É exatamente esse tipo de auditoria pré-contratual que parceiros como a Vertis Tech desenham desde o discovery, em vez de tratar LGPD como camada aparafusada no fim.
O pipeline real do dado pessoal num sistema de IA aplicada
Antes de discutir compliance, vale recompor o trajeto técnico que o dado faz num agente ou RAG corporativo comum. O decisor que entende esse trajeto consegue avaliar uma proposta de IA com a mesma seriedade com que avalia uma integração fiscal — porque o risco é da mesma natureza, tratamento de dado pessoal sob responsabilidade dele como controlador.
Num projeto típico de chatbot WhatsApp com base de conhecimento ou agente de IA com tools, o dado pessoal do cliente final transita por algo próximo a:
- Captura — formulário no site, mensagem no WhatsApp, telefone informado no atendimento, dados puxados de CRM existente.
- Persistência operacional — banco relacional do sistema (PostgreSQL, MySQL), tabelas de contato, conversa, ticket, sessão.
- Indexação semântica — quando o sistema é RAG, trechos relevantes da conversa ou do histórico do cliente viram chunks, são processados por um modelo de embedding e armazenados como vetores num banco vetorial (pgvector, Qdrant, índice próprio).
- Inferência — pra cada pergunta nova, o sistema recupera chunks similares, monta um prompt com o nome, o CPF, o histórico, ou o trecho de conversa anterior do cliente, e envia ao LLM (Claude, GPT, Gemini, Groq, Llama hospedado, etc.).
- Resposta e ação — o LLM devolve resposta ou aciona uma tool que, por sua vez, escreve no CRM, agenda, dispara cobrança, manda WhatsApp.
- Auditoria e log — toda a interação fica gravada em log estruturado, mensagem do WhatsApp persiste no provedor de WhatsApp (Cloud API oficial Meta ou parceiro), prompt enviado ao LLM pode ficar retido conforme política do provedor.
Cada uma dessas seis camadas é, isoladamente, tratamento de dado pessoal sob LGPD. Cada uma exige base legal, finalidade documentada e prazo de retenção definido. E cada uma reage de um jeito diferente quando o titular exerce direito do art. 18 — acesso, correção, exclusão, portabilidade.
Onde o controle costuma escapar
Quatro pontos concentram a maior parte das surpresas que aparecem em auditoria, processo administrativo ou pedido de exclusão de titular.
Ponto 1 — Persistência operacional sem retenção parametrizada.
O banco relacional é o terreno mais bem compreendido. O DPA típico cobre. O problema costuma ser a ausência de retenção configurável por finalidade. Cliente final fechou contrato — finalidade comercial encerrou. A conversa qualificadora dele ainda está lá, há 18 meses, porque "ninguém implementou rotina de expurgo". Tecnicamente é reversível (UPDATE, DELETE, soft delete com anonimização posterior), mas só funciona se o sistema foi desenhado pra distinguir dados ativos de dados em retenção pós-finalidade.
Ponto 2 — Embedding vetorial não é anonimização.
Aqui está o ponto onde a maior parte dos fornecedores de IA não conversa de igual com o jurídico do contratante. Quando o sistema é RAG, trechos de conversa, e-mails ou documentos do cliente final viram vetores num índice. O argumento de que "vetor é representação matemática, não é dado pessoal" não se sustenta operacionalmente — o chunk de texto original costuma estar armazenado junto, indexado pelo vetor, justamente pra ser recuperado e injetado no prompt. E mesmo quando só o vetor sobrevive, ele continua sendo dado pessoal sob LGPD, porque vincula a um titular identificável dentro do sistema.
A consequência prática: quando o titular pedir exclusão, deletar a linha do CRM não basta. O fornecedor precisa ter, no desenho do sistema, uma operação de re-indexação ou de remoção seletiva no índice vetorial — e isso quase nunca está descrito em proposta comercial. É um trabalho técnico não trivial, que precisa ser combinado em contrato. A regulação americana e europeia já enfrenta esse debate; a ANPD ainda não publicou diretriz específica, mas a Nota Técnica 12/2025 já demonstra a direção.
Ponto 3 — Prompt enviado ao LLM e a jurisdição do provedor.
Esse é o ponto onde a transferência internacional de dados acontece sem alarme. O sistema monta um prompt que inclui dados do cliente final ("Olá, sou o atendente. O cliente Maria Silva, CPF XXX, contratou o plano Y em fevereiro, hoje ligou perguntando Z"), e envia esse prompt à API do provedor LLM. Esse provedor processa em infraestrutura própria, em jurisdição própria, sob política de retenção própria.
Pra contratos comerciais B2B, os provedores hyperscaler principais oferecem termos com retenção zero de prompts ou retenção restrita pra abuso, e cláusulas de transferência internacional compatíveis com LGPD. Mas isso precisa estar contratado explicitamente — não é configuração default em conta gratuita, não está garantido em provedor de baixo custo, e não existe pra modelo hospedado por terceiro intermediário sem DPA próprio. O decisor que assina o projeto de IA precisa saber qual provedor LLM vai ser usado, qual conta, qual termo comercial vigente, e por quanto tempo o prompt fica retido. Resposta evasiva é red flag.
Ponto 4 — Conversa no WhatsApp, transcrição e log estruturado.
O WhatsApp é o canal onde a confusão de papéis aparece com mais frequência. Quando a operação roda via WhatsApp Cloud API oficial da Meta, a Meta é subprocessadora — com termos próprios, retenção própria, infraestrutura própria. Quando roda via parceiro de QR Code (uazapiGO e similares), o parceiro é outro subprocessador, com outro contrato. Mensagens recebidas e enviadas ficam armazenadas em algum desses provedores, pelo prazo definido por eles, e a empresa contratante precisa ter mapa explícito dessa cadeia no seu registro de operações de tratamento (art. 37 LGPD).
Some-se a isso o log estruturado da aplicação — que normalmente registra prompt enviado, resposta recebida, tool executada, parâmetros. Esse log é dado pessoal puro, costuma viver em sistema de observabilidade (Loki, Datadog, CloudWatch), e raramente tem retenção parametrizada por finalidade.
O que mudou em 2025-2026 e por que importa agora
A leitura mais comum no comitê é "LGPD existe desde 2020, já lidamos com isso". Em projeto de IA, essa leitura é insuficiente. Três sinais regulatórios recentes reorganizam o cálculo de risco.
Primeiro, a Agenda Regulatória 2025-2026 da ANPD lista, explicitamente, inteligência artificial como tema prioritário, ao lado de relatório de impacto, decisões automatizadas (art. 20), anonimização e tratamento de alto risco. A Autoridade está reorganizando o foco fiscalizatório.
Segundo, a Nota Técnica nº 12/2025 da ANPD consolidou contribuições sobre tratamento automatizado e IA. O documento não cria obrigação nova, mas indica para onde a Autoridade vai apontar a fiscalização: finalidade declarada, retenção justificada, base legal adequada, transferência internacional controlada, due diligence em fornecedor, contrato com cláusulas explícitas sobre uso dos dados, e revisão humana em decisão automatizada crítica.
Terceiro, fiscalizações já ativas em 2026 contra provedores de IA generativa em outros países criaram precedente que costuma se replicar regionalmente — auditoria de base legal pra treinamento, ordem de exclusão de dados de titulares europeus de bases de fine-tuning, restrição de transferência. A ANPD acompanha e tende a aplicar princípios análogos.
A consequência prática pro decisor que está pra assinar projeto de IA hoje: a janela em que "vamos ajustar LGPD depois" custava barato está fechando. Contratar agora um fornecedor que não tem o pipeline desenhado com LGPD desde o discovery costuma virar débito técnico caro de reverter em 12 a 18 meses.
O que pedir ao fornecedor de IA no contrato
A pergunta certa não é "vocês são LGPD-compliant". Toda proposta vai responder sim. As perguntas que filtram fornecedor sério costumam ser:
Sobre papéis e cadeia. Quem é controlador e quem é operador nesse contrato? Quais subprocessadores aparecem (provedor de LLM, provedor de WhatsApp, banco vetorial, observabilidade)? Os DPAs deles estão anexados? Qual jurisdição cada um opera?
Sobre o pipeline do dado. Mostre o caminho técnico de um nome e CPF do meu cliente desde o formulário até o último log. Em que tabelas relacionais ele aparece? Em que momento entra num índice vetorial? Que parte vai pro prompt do LLM? Onde fica o log estruturado da inferência?
Sobre retenção. Cada um desses pontos tem prazo de retenção parametrizado por finalidade? Existe rotina automática de expurgo? O índice vetorial é re-construído periodicamente ou tem operação seletiva de remoção?
Sobre exclusão do titular. Quando meu cliente final pedir exclusão sob art. 18, qual é o procedimento? Quanto tempo demora? Inclui re-indexação do banco vetorial? Inclui ordem de exclusão pro provedor de WhatsApp?
Sobre transferência internacional. Qual conta no provedor LLM é usada? Qual é o termo comercial vigente sobre retenção de prompt e uso pra treinamento? Em que país a inferência roda?
Sobre decisão automatizada. Onde o sistema decide algo sobre o titular sem revisão humana (priorizar atendimento, marcar como inadimplente, classificar como hot lead)? Existe trilha pro art. 20 — revisão humana, justificativa, possibilidade de impugnação?
A diferença entre fornecedor que respira LGPD e fornecedor que cola LGPD na entrega aparece nessas respostas em poucos minutos.
Como a Vertis Tech ajuda em LGPD em projetos de IA
A Vertis Tech é fábrica de software brasileira focada em CRM, automação e IA aplicada. Cada projeto é dimensionado conforme sensibilidade dos dados tratados, jurisdição de operação, integrações necessárias e maturidade de governança do cliente. A depender do escopo, a implantação pode contemplar:
- Discovery com mapeamento explícito do pipeline de dado pessoal, traçando o caminho da informação do ponto de captura até o último log antes de comprometer arquitetura.
- Multi-tenant rigoroso desde a primeira tabela, com isolamento de dados por contratante e auditoria de acesso preservada por design.
- Retenção parametrizada por finalidade, com rotinas de expurgo combinadas em escopo, não improvisadas depois.
- Governança de cadeia de subprocessadores documentada, mapeando provedor de LLM, provedor de WhatsApp, banco vetorial e observabilidade — com DPAs vigentes anexados ao contrato.
- Operação de exclusão de titular que alcança índice vetorial e logs, desenhada antes da entrada em produção, não como reação ao primeiro pedido.
- DPO designado (dpo@vertis.tech) e canal formal pra exercício de direitos do titular, com prazo e procedimento documentados.
Perguntas frequentes
O embedding vetorial é considerado dado pessoal sob LGPD?
Em sistemas RAG corporativos, sim — e por dois motivos. Primeiro, o chunk de texto original costuma estar armazenado junto com o vetor, justamente pra ser recuperado e injetado no prompt; nesse caso, o dado pessoal está fisicamente presente, e o embedding só é o índice. Segundo, mesmo quando só o vetor sobrevive, ele permanece vinculado a um titular identificável dentro do sistema, o que mantém o regime LGPD. A consequência operacional é que o direito de exclusão precisa contemplar remoção seletiva no índice ou re-indexação completa.
Posso usar legítimo interesse como base legal pra treinar modelo com dados de cliente?
Depende da finalidade e do tipo de tratamento. Inferência sobre conversa em tempo real pra responder o próprio cliente costuma ser execução de contrato ou legítimo interesse compatível. Uso de conversa de cliente pra treinar ou fazer fine-tuning de modelo que vai ser reutilizado pra outros contratantes é outra história — exige análise de finalidade, balanceamento e, em muitos casos, consentimento específico. A Nota Técnica 12/2025 da ANPD pede documentação detalhada nesses casos. Recomenda-se avaliação com DPO ou jurídico especializado antes de fechar a base legal em contrato.
Provedor de LLM internacional inviabiliza projeto de IA pra empresa brasileira?
Não inviabiliza, mas exige cuidado contratual. Os principais provedores oferecem termos comerciais B2B com retenção restrita ou zero de prompts, cláusulas de transferência internacional compatíveis com LGPD e DPAs próprios. O que inviabiliza é usar conta gratuita ou intermediário sem DPA pra processar dado pessoal de cliente final. A decisão entre LLM externo, modelo aberto auto-hospedado ou solução híbrida costuma combinar sensibilidade do dado, custo de inferência e maturidade da operação.
O que muda quando o WhatsApp é Cloud API oficial Meta versus parceiro de QR Code?
O regime de subprocessador muda. Na Cloud API oficial, a Meta é subprocessadora direta, com termos próprios, infraestrutura própria e retenção definida por ela. No parceiro de QR Code (uazapiGO e similares), há um intermediário a mais na cadeia, com contrato e infraestrutura próprios. Ambos podem ser configurados de forma compatível com LGPD, mas o registro de operações de tratamento (art. 37) precisa refletir exatamente o caminho usado. O decisor precisa saber qual caminho está contratado.
Quando vale a pena contratar um Relatório de Impacto à Proteção de Dados (RIPD) pra projeto de IA?
A LGPD não exige RIPD pra todo projeto, mas ele costuma ser indicado quando o sistema toma decisão automatizada com efeito sobre o titular, processa dado sensível, ou opera em escala que envolve risco aumentado. A Agenda Regulatória 2025-2026 da ANPD coloca o RIPD entre os temas prioritários, e a tendência é que o documento se torne expectativa formal pra projeto de IA conversacional empresarial. Vale o investimento quando o projeto roda em setor regulado, atende cliente final em volume relevante, ou tem decisão automatizada no fluxo crítico.
LGPD em projeto de IA não é camada aparafusada depois — é eixo de arquitetura desde o discovery. O contrato que entra em produção sem mapa do pipeline do dado vira passivo silencioso, e a ANPD já sinalizou que vai olhar pra esse tipo de tratamento com mais atenção nos próximos ciclos de fiscalização. O decisor que sair da próxima reunião com o fornecedor sabendo descrever, em uma página, o caminho do nome e CPF do cliente final desde o formulário até o último log já está em posição melhor que a média do mercado pra avaliar a proposta.


